


深度学习 – 监督学习、半监督学习、无监督学习、自监督学习、强化学习等机器学习方式的概念、区别、优缺点
在机器学习中,有几种主要的学习方式:监督学习、无监督学习、半监督学习、自监督学习和强化学习等,本文将详细介绍这几种学习方式的概念和优缺点。 1 机器学习方式 1.1 监督学习 监督学习(Supervised Learning)利用大量的标注数据来训练模型,通过对已有标记数据进行学习,训练模型可以对未…
- 深度学习
- 2023-06-25
深度学习 – 归纳轻量级神经网络(长期更新)
SqueezeNet 论文标题:SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size 论文: Iandola F N, Han S, Moskewicz M W, et al. S…
- 深度学习
- 2023-03-17
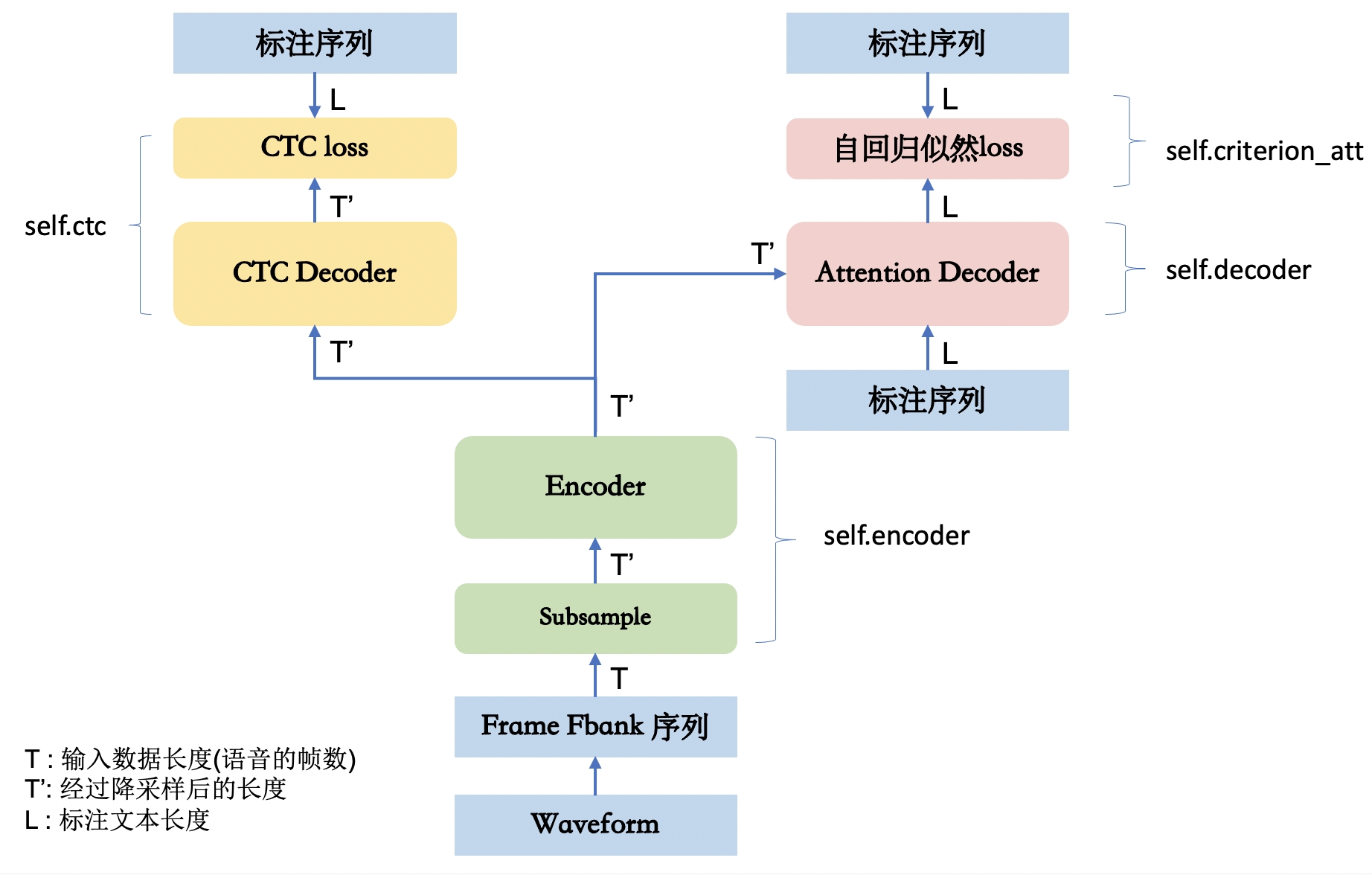
深度学习 – 语音识别框架Wenet网络设计与实现
转载自Wenet网络设计与实现,这个文章是Wenet团队对Wenet比较全面的介绍,也在很多地方解答了我在看wenet源码时的疑惑,会时不时翻出来再看的文章,但是这个文章是托管在Github上的,所以为了防止某些不可控的原因导致无法阅读原文,所以在本站对原文进行完整备份,仅用于个人阅读,如果原作者认…
- 深度学习
- 2023-01-13
深度学习 – 语音识别框架wenet中的CTC Prefix Beam Search算法的实现
1 Wenet中的CTC Prefix Beam Search Decode的实现 下面是Wenet网络的流程图 上图来自于:http://placebokkk.github.io/wenet/2021/06/04/asr-wenet-nn-1.html 语音特征数据在经过Encoder后会使用CT…
- 深度学习
- 2023-01-13
深度学习 – 为什么要初始化网络模型权重?
1 为什么要进行网络模型权值初始化? Pytorch中设计好网络结构,并搭建完成之后通常一个重要的步骤就是需要对网络模型中某些层的权值进行初始化,如下代码所示,我们搭建了一个三维卷积网络C3D,并使用私有成员函数__init_weight对网络中的nn.Conv3d和nn.BatchNorm3d模块…
- 深度学习
- 2022-08-26
深度学习 – 图像标准化与归一化方法
如果深度学习的源数据为图像数据时,首先需要对图像做数据预处理,最常用的图像预处理方法有两种,正常白化处理又叫图像标准化处理,另外一种方法为图像归一化处理,本文将对这两种预处理方法进行简要介绍。 1 图像标准化 图像标准化处理公式如下: \text{image} = \frac{image - \mu…
- 深度学习
- 2022-08-22
深度学习 – 语音识别框架wenet的非流式与流式混合训练机制
1 wenet的非流式与流式混合训练机制 wenet实现了语音识别非流式与流式混合训练的机制。通过细读源码,其主要是通过动态修改网络的Encoder层(在wenet中主要使用了TransformerEncoder和Conformer)的attention mask来影响Encoder层中Self-A…
- 深度学习
- 2022-08-11
深度学习 – 语音识别框架wenet源码wenet/utils/mask.py中的mask机制
在阅读工业级语音识别框架wenet的源码的过程中,wenet/utils/mask.py中提供的各种mask函数非常重要,其实现了wenet论文Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recog…
- 深度学习
- 2022-08-10

Transformer – 理解Transformer必看系列之,2 Positional Encoding位置编码与Transformer编码解码过程
转载自: 链接:https://www.ylkz.life/deeplearning/p10770524/ 作者:空字符 少量行文修改 1 引言 经过此系列上一篇文章Transformer - 理解Transformer必看系列之,1 Self-Attention自注意力机制与多头注意力原理的介绍,…
- Transformer
- 2022-08-02
Transformer – 理解Transformer必看系列之,1 Self-Attention自注意力机制与多头注意力原理
转载自: 链接:https://www.ylkz.life/deeplearning/p10553832/ 作者:空字符 修改文章少量行文 1 引言 今天要和大家介绍的一篇论文是谷歌2017年所发表的一篇论文,名字叫做Attention is all you need,当然,网上已经有了大量的关于这…
- Transformer
- 2022-08-01

深度学习 – 以一个极简单的中英文翻译Demo彻底理解Transformer
转载自: 原文链接:https://zhuanlan.zhihu.com/p/360343417 作者:Algernon 少量行文修改。 Transformer并没有特别复杂,但是理解Transformer对于初学者不是件容易的事,原因因在于Transformer的解读往往没有配套的简单的demo,…
- Transformer
- 2022-07-29

深度学习 – 从矩阵运算的角度理解Transformer中的self-attention自注意力机制
转载自https://zhuanlan.zhihu.com/p/410776234 之前我对Transformer中的Self-Attention的机制也是看了很多遍论文,看了很多博文的解读,直到看到了这篇博文,让我醍醐灌顶,打通了任督二脉,果然将复杂问题讲复杂每个人都会,但是从基础的角度将复杂问题…
- Transformer
- 2022-07-20